
(Release v1.0. August 2013.)
(Release v1.1. August 2014. – Released evaluation software, video sequence synchronization, pedestrian detection data and body-part detection data)
(Release v1.2. January 2015 – Improved the training sample set, added toy train and test datasets.)
Release v1.3. November 2015 – Added homographies for each camera (projection from the camera image to the ground plane).
Maintained by Alexandre Bernardino (alex at isr ist utl pt). Contact me if you are interested in this dataset.
Keywords: Video Surveillance, Pedestrian Detection, Re-identification, Multi-Camera Tracking, Benchmarking.
Related publications:
- A Multi-camera video data set for research on High-Definition surveillance, Int. J. of Machine Intelligence and Sensory Signal Processing, 2014.
- The HDA+ data set for research on fully automated re-identification systems, ECCV workshop, 2014.
The HDA dataset is a multi-camera high-resolution image sequence dataset for research on high-definition surveillance. 18 cameras (including VGA, HD and Full HD resolution) were recorded simultaneously during 30 minutes in a typical indoor office scenario at a busy hour (lunch time) involving more than 80 persons. In the current release (v1.1), 13 cameras have been fully labeled.


















The venue spans three floors of the Institute for Systems and Robotics (ISR-Lisbon) facilities. The following pictures show the placement of the cameras. The 18 recorded cameras are identified with a small red circle. The 13 cameras with a coloured view field have been fully labeled in the current release (v1.1).
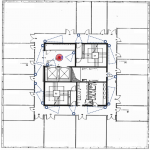
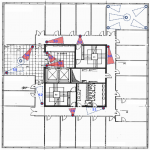

Each frame is labeled with the bounding boxes tightly adjusted to the visible body of the persons, the unique identification of each person, and flag bits indicating occlusion and crowd:
- The bounding box is drawn so that it completely and tightly encloses the person.
- If the person is occluded by something (except image boundaries), the bounding box is drawn by estimating the whole body extent.
- People partially outside the image boundaries have their BB’s cropped to image limits. Partially occluded people and people partially outside the image boundaries are marked as ‘occluded’.
- A unique ID is associated to each person, e.g., ‘person01’. In case of identity doubt, the special ID ‘personUnk’ is used.
- Groups of people that are impossible to label individually are labelled collectively as ‘crowd’. People in front of a ’crowd’ area are labeled normally.
The following figures show examples of labeled frames: (a) an unoccluded person; (b) two occluded people; (c) a crowd with three people in front.



Data formats:
For each camera we provide the .jpg frames sequentially numbered and a .txt file containing the annotations according to the “video bounding box” (vbb) format defined in the Caltech Pedestrian Detection Database. Also on this site there are tools to visualise the annotations overlapped on the image frames.
Some statistics:
Labeled Sequences: 13
Number of Frames: 75207
Number of Bounding Boxes: 64028
Number of Persons: 85
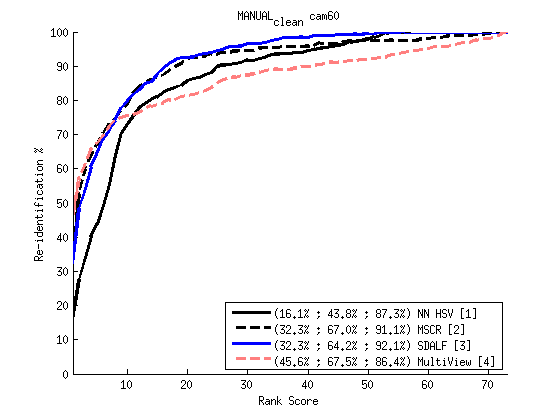
Repository of Results:
We maintain a public repository of re-identification results in this dataset. Send us your CMC curve to be uploaded (alex at isr ist utl pt).
Click here to see the full list and detailed experiments.
FAQ:
No questions yet.
Credits:
We acknowledge with many thanks all the participants in the recording and labelling sessions: Matteo Taiana, Dario Figueira, Athira Nambiar, Jacinto Nascimento, Alexandre Bernardino, José Gaspar, Ricardo Galego, João Gomes, Giovanni Saponaro, Plinio Moreno, Fábio Reis, André Grilo, Nuno Moutinho, Duarte Aragão, Jonas Ruesch, Bruno Damas, Feng Zhou, Ricardo Nunes, Ana Santos, Susana Santana.
We thank all the anonymous persons who were caught in the recordings and authorised the use of their images for scientific research purposes.
This work was partially funded by Portuguese Government through project High Definition Analytics (HDA), QREN – I&D em Co-Promoção nr. 13750.
![]()

